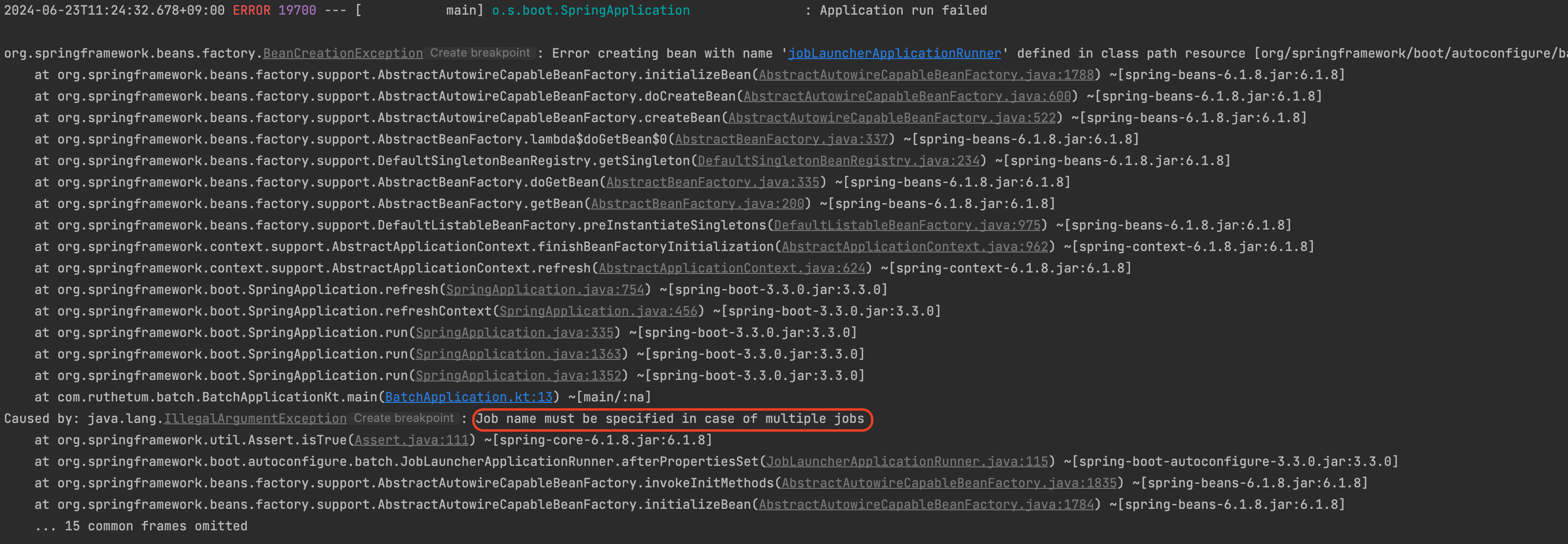
728x90
AOP(Aspect Oriented Programming)
- OOP를 보완하는 수단으로, 흩어진 Aspect를 모듈화할 수 있는 프로그래밍 기법

- 동일한 기능이 흩어져 있으면 유지보수하는데 어려움이 존재
- 각 클래스 내에 흩어진 관심사를 묶어서 모듈화
- 애플리케이션 전체에 걸쳐 사용되는 기능을 재사용
AOP 주요 용어
- Aspect : 관심사를 모듈화한 것
- Target : 적용이 되는 대상
- Advice : 해야할 일(실제 수행되는 코드)
- Join point : 메서드 실행 시점(Advice를 실제로 실행하고자 하는 위치)
- Pointcut : 대상 내에 어디에 적용이 되어야 하는지에 대한 정보(Join point를 선정하는 방법)
- Weaving : Aspect가 target에 적용되는 전체적인 과정, PointCut으로 지정된 JoinPoint에 Advice가 적용되어 Target을 호출 시 AOP Proxy가 만들어지는 과정

AOP 구현체
- https://ko.wikipedia.org/wiki/%EA%B4%80%EC%A0%90_%EC%A7%80%ED%96%A5_%ED%94%84%EB%A1%9C%EA%B7%B8%EB%9E%98%EB%B0%8D#%EA%B5%AC%ED%98%84
- Java
- AspectJ
- Spring AOP
- Java
AOP 적용 방법
- 컴파일
- 로드 타임
- 런타임
Spring AOP가 사용하는 방법 → 런타임 (Dynamic Proxy 기법으로 구현)
- A라는 Class 타입의 Bean을 생성할 때, A 타입의 Proxy Bean을 생성
- AOP가 적용된 Target 메서드를 호출 할 때 실제 메서드가 호출되는 것이 아니라 Advice가 요청을 대신 랩핑(Wrraping) 클래스로써 받고 그 랩핑 클래스가 Target을 호출
Spring AOP : Proxy 기반 AOP
Spring AOP의 특징
- 프록시 기반의 AOP 구현체
- 스프링 빈에만 AOP를 적용할 수 있음
- 모든 AOP 기능을 제공하는 것이 목적이 아니라 스프링 IoC와 연동
프록시 패턴

- 프록시 패턴을 적용하는 이유 : 기존 코드 변경없이 접근 제어 또는 부가 기능 추가
만약 성능(시간)을 측정하는 기능을 추가해야 한다면?
@Service
public class EventServiceImpl implements EventService {
@Override
public void createEvent() {
long begin = System.currentTimeMillis();
try {
Thread.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("Created an event");
System.out.println(System.currentTimeMillis() - begin);
}
@Override
public void publishEvent() {
long begin = System.currentTimeMillis();
try {
Thread.sleep(2000);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("Published an event");
System.out.println(System.currentTimeMillis() - begin);
}
@Override
public void deleteEvent() {
System.out.println("Deleted an event");
}
}- 성능(시간)을 측정하는 부가적인 기능을 추가할 경우 기존 코드를 수정해야 하는 상황이 발생
- 프록시 패턴을 이용하여 기존 클래스를 두고 프록시 클래스를 작성하여 기능을 위임하고 부가적인 기능을 작성할 수 있음
@Primary
@Service
@RequiredArgsConstructor
public class ProxyEventServiceImpl implements EventService {
private final EventServiceImpl eventServiceImpl;
@Override
public void createEvent() {
long begin = System.currentTimeMillis();
eventServiceImpl.createEvent();
System.out.println(System.currentTimeMillis() - begin);
}
@Override
public void publishEvent() {
long begin = System.currentTimeMillis();
eventServiceImpl.publishEvent();
System.out.println(System.currentTimeMillis() - begin);
}
@Override
public void deleteEvent() {
eventServiceImpl.deleteEvent();
}
}- 프록시 클래스를 활용하여 기능을 위임
- 하지만 이 경우에 모든 클래스에 대해 프록시 클래스를 작성해야 하는 비용이 발생
- 추가로 프록시 클래스 내에도 동일한 기능에 대한 중복 코드가 발생하고 다른 클래스에서 재사용이 어려움
Spring AOP 등장 배경
- 이러한 문제를 Spring IoC Container가 제공하는 기반 시설과 Dynamic Proxy를 사용하여 해결
- 동적 프록시 : 동적으로 프록시 객체를 생성하는 방법
- Java가 제공하는 방법 : Interface 기반 Proxy 생성
- Spring IoC : 기존 Bean을 대체하는 Dynamic Proxy Bean을 만들어 등록 시켜줌
- 클라이언트 코드 수정 없음
AbstractAutoProxyCreator implements BeanPostProcessor
Proxy Bean 생성 과정
- 원본 클래스의 Bean이 등록
- AbstractAutoProxyCreator을 통해 원본 클래스를 감싸는 Proxy Bean을 생성
- Proxy Bean을 원본 클래스의 Bean 대신에 등록
@AOP
- 애노테이션 기반의 스프링 AOP
의존성 추가
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-aop'
}
Aspect 정의 : @Aspect
- Bean으로 등록해야 하므로 (컴포넌트 스캔을 사용한다면)
@Componet도 추가
PointCut 정의
execution
- ex.
@Around("execution(* com.example..*.EventService.*(..))") - execution은 기존 코드를 완전히 건드리지 않고 aspect 내에 작성된 표현식으로 기능을 수행할 수 있음
- 하지만 pointcut 조합이 어려움
- ex. &&, ||, !
@annotation
- ex.
@Around("@annotation(PerfLogging)") - 애노테이션 내
@RetentionRetentionPolicy.CLASS: 애노테이션 정보가 바이트 코드까지 남아 있음 (default)RetentionPolicy.SOURCE: 컴파일 후에 사라짐RetentionPolicy.RUNTIME: 런타임까지 유지 (굳이 할 필요 없음)
- 애노테이션을 정의하고, 해당 애노테이션을 원하는 메소드에 추가
Example
// aspect
@Aspect
@Component
public class PerfAspect {
// @Around("execution(* com.example..*.EventService.*(..))") // execution
@Around("@annotation(PerfLogging)")
public Object logPerf(ProceedingJoinPoint pjp) throws Throwable {
long begin = System.currentTimeMillis();
Object retVal = pjp.proceed();
System.out.println(System.currentTimeMillis() - begin);
return retVal;
}
}
// interface
@Documented
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.CLASS)
public @interface PerfLogging {
}
// service
@Service
public class EventServiceImpl implements EventService {
@PerfLogging
@Override
public void createEvent() {
try {
Thread.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("Created an event");
}
...
}cf. pointcut 관련
- https://docs.spring.io/spring-framework/docs/2.5.x/reference/aop.html
- http://ldg.pe.kr/framework_reference/spring/ver2.x/html/aop.html
참고
728x90
'Spring' 카테고리의 다른 글
| [Spring] @Cacheable, @CachePut, @CacheEvict (0) | 2024.08.17 |
|---|